2025年の振り返り
2025年はいろんなことがあった。
第二子👶
妻が第二子を妊娠した。 妊娠がわかったのが2月。
一人目のときもつわりがひどく、 二人目も残念ながらつわりが出た。
今回は一人目もいてのことなので、家事育児が妻が思うようにできなくなってしまった。
結果として、急遽自分が1ヶ月仕事を休むことにした。
幸い会社の制度で休めたのでよかった。 職場には迷惑をかけたが、休んで本当によかった。 (というか休む制度がなかったら最悪仕事を辞めていたかもしれないなと思う)
つわりのひどい時期をだいぶサポートできたが、1ヶ月では休みが足らないくらいではあった。 (つわりは治らなかった)
基本的に家事育児をしてたら一瞬で時間は過ぎ去り、1ヶ月の間、自己研鑽には全く時間を使えなかった。
中古戸建を買って引越した🏠
子供が二人になると確定し、2LDKのマンションに住み続けるのは困難になった。
マンションは、3LDKだとしてもリモートワークのスペース確保を考えたり、車を持つことを考えると、なかなかマンションには決められなかった。
戸建となると、土地と上物で値段を考えると都心からの距離が離れてしまい、決めきれない。
かなり迷ったが結果的に関東を離れて地方移住した。
家は中古戸建にした。 地方とはいえ、アクセスや広さを考えると新築戸建を建てる余裕はなく、中古の戸建てを購入した。
いろいろ物件をスーモで見て問い合わせしまくった結果、いい家ではなくいい不動産屋さんに巡り会えたのがデカかった。
不動産屋さんにいろいろ仲介を頑張ってもらって、住みたいと思える中古戸建にであえてよかった。
出産というリミットがあるので決めきれた部分も大きい。 保育園の転園は必要になるが、学校の転校よりはマシと判断。
学校周りで言えば、お受験を避けたくて地方にした部分もある。
実家には近づいてはいるが、実家の近くではないので依然として親を毎日のように頼れる状態ではない。
都心にも出られる範囲の地方を選んだ。 (だから土地が結構高かったのもあると思う)
中古戸建をいざ買うまでの壮絶なエピソードは別で書く予定。
7月末に物件の引き渡し、8月に引っ越しとなった。
会社の夏季休暇に合わせて暑い中だったが、時間をかけて荷造り・荷解きして引っ越しができた。
お互いの両親に頼りつつ、最低限住めるような整理ができた。 妊婦と小さい子供がいながらの引っ越しは大変だなと思った。
妻は引っ越しの時期には産休に入っていて、引越しが終わって少しして里帰りになった。
一人目は8月の引越し月は転園に失敗(近くの保育園に空きがなかった)し、役所に相談したりして9月から小規模保育園に入ることになった。
とはいえ、ママが里帰り、パパはフルタイムで仕事という状況もあり、1週間慣らし保育したら、上の子は一緒に里帰りしてもらった。
後述するが、赤ちゃんが生まれてからは上の子だけ戻ってきてパパとワンオペ保育園生活となる。
第二子の出産👶
10月初旬に第二子の出産があった。 バタバタしつつ、ほとんど予定日通りに出産となった。 一人目と違う産院で、無痛分娩を選んだ。 無痛分娩にも種類があり、人にもよるとは思うが、割と痛みがある出産になった。
仕事は11月〜1月末までを育児休職に、10月後半は有給という形で休むことにした。 生まれてからは義実家でママと赤ちゃん、新居でパパと長女という形態を採った。
新居でママと離れてパパと暮らしながら、慣れない家と慣れない保育園に通う生活は3歳には相当ストレスだったと思うが、とてもいい子に頑張ってくれた。
今はもう1ヶ月検診を無事に終えて、里帰りから新居に戻って家族4人の生活になっている。
子供二人と育休生活
一人目がいるので、育休とはいえ赤ちゃんの面倒ばかりを見ているわけではない。
基本的に、むしろママは母乳をあげる使命があるので、必然的にママは赤ちゃん、パパはお姉ちゃんの面倒を見る感じになっている。
上の子がいない保育園の間に両親二人がかりになる沐浴は済ませたくて、14時半ごろから沐浴するようにしてる。
休んでから知ったのだが、育休中は保育時間が短時間になってしまうため、基本の預け入れが8時〜16時になる。
お迎えに行く時間も考えると、15時半にはお迎えに行くことになるので、ほとんど午後はお昼ご飯を食べたらすぐ沐浴で、お迎えになる形。
上の子が帰ってきたら寝るまでつきっきりなので、21時か22時くらいまでは両親ともにいてもノンストップで時間が過ぎ去っていく。
仕事に復帰できる気がしない…。
考えたこととまとめ
二人目ができたことで、これからの人生の舵取りを考えざるを得なくなった。 0か100かではないものの、住む場所によって家庭に重きを置くか、仕事に重きを置くかは考えた。
地方移住でキャリアを登るのはとても難しいだろうなとは思いかなり悩んだものの、自分のキャリアよりも子供にとって良いのはどちらか考えて決断した。
一人目の時の育児休職は、育児にバタバタしてるだけだったが、二人目の育児休職はちょっと違っていた。
もちろん一人目の育児も増えているので大変さは倍増しているのだが、どちらかというと赤ちゃんへの接し方に対して気持ちに余裕がある。
一人目のときから授乳以外すべてできるようになっていたので、二人目でもほとんど自分だけで赤ちゃんの世話はできる。
一人目の面倒も自分だけで見られるし、里帰り後半の数週間はワンオペで上の子を見ていた。
その結果、二人の子供に接しながら感じたのは、とてつもなく子供たちが可愛いということだった。
特に上の子は、平日は、朝起きてすぐ保育園に送ってしまって、夜仕事を終えてから少し顔を見るくらいの生活だった。
育休ワンオペ期間は、保育園にお迎えして、お風呂やご飯、一緒に遊ぶ時間を過ごせて、3歳になってこんなにできることも増えて表現が豊かになったんだ、と毎日感動した。 (もちろんアホほど怒れることするし、叱ることも多いのだが…)
育休を取らなかったらこれが味わえなかったのかと思うと、本当に育休をとって良かったと思うし、仕事復帰したら見られなくなるのかと思うと、とても悲しい。
そういったことも踏まえて、自分は仕事以上に子供と接する時間を増やしながら、人生を歩んでいくことになるんだろうなと思う。
キャリアで言えば(副業とか対外活動してないので当たり前なのだが)、一時期に比べて外からお声がかかることがほとんどなくなった。
これに加えて出社回帰の中、地方移住しているので、もはや選ぶような転職は絶望的な気もする。
そんな中で自分がより理想的に、どういう仕事のキャリアを描いていけるかは、自分としても楽しみだったりする。
2歳児の子育ての振り返り
前書き
子供がめでたくもうすぐ3歳になるという今のタイミングで、 子育ての現状を書き残しておこうと思います。
特に誰かに読んでもらいたいというよりは、将来自分が見返すことを想定して書き残します。
うちの家庭、うちの子の独自な部分もたくさんあると思いますので、もし読まれる方は参考程度にしてください。
2歳児の子育て
とある平日の過ごし方
07:00 起床→朝の準備 07:30 朝食 08:30 登園 09:30 後片付け 10:00 仕事開始 16:30 仕事中断→お迎え 17:30 仕事再開 19:00 仕事終了→子供とご飯 20:00 子供とお風呂 21:00 寝かしつけ 22:30 子供が就寝→後片付けや家事と登園準備 23:00 自由時間(夫婦の会話や、残っていた仕事をするなど) 00:00 就寝
育児の方針
育児って大変だなと思うこと
寝ない
一番困るのは 夜に寝ないこと です。 極限まで疲れればもちろん寝るのだけど、眠いな、くらいの状態だと「寝たくない」が勝って寝ません。 特に保育園で2時間程度お昼寝するので、夜も普通に元気で過ごせてしまう日も多いです。
これは嬉しいことではあるんですけど、もっとパパと遊びたいから寝たくないと言って寝ないです。 最近は布団にいくと「もっと遊びたかった」と泣いて寝る日も多いです。
寂しがりやで、パパとママ両方いないと布団で寝られないので、二人揃って寝かしつけしています。 これも結構大変で、どちらかが寝かしつけの間、仕事や家事に戻ることができないという大変さがあります。
22時半くらいになると親も疲れてくるのでいっそ一緒に寝る日もあります。
もう13kgになりますが、0歳児の頃と変わらずパパのお腹の上で寝ることもあります。
ちなみに、保育園に対して「お昼寝短くしてください」と2、3回お願いしました。 こちらの要望としては、「1時間程度で起こしてほしい」という依頼だったのですが、 「寝かしつけをしない(トントンせず放置する)」という対応だけされてしまって、ただ子供がちょっとかわいそうなだけになってしまいました…。
体調が悪くなる
保育園で感染症が広がると必ずと言って良いほどもらって帰ってきます。 手洗い・うがいはさせているものの、どうしても2歳の間、平均で月に1回くらいは熱が出ていたように思います。
その時は、父母のどちらかが会社を休む必要があるので、仕事の調整を余儀なくされます。 親への感染もリスクなので気をつけてはいるものの、よだれや鼻水のついた手でがっつり粘膜を触れることも多々あるので、 親も熱が出てしまうことも多々あった。そうなると、救いようがないですね。。。
上の夜寝ない話も繋がっていて、睡眠時間が短くなるとより体調に現れやすい(ので、早く寝てほしい)です。
両親(爺婆)が遠い
親子どちらかが体調が悪いときに両親が近くに住んでいればサポートしてもらえるものの、どちらも遠方であるがゆえに助けてもらいづらいです。
ちなみに病児保育も一度頼もうとしたことはあるが、診断書が必要(結局親が休んで病院に連れていく必要があるんかい)だったり普通に予約が空いてなかったりして気軽に頼めるようなものではありませんでした。
パパママへの指名制度
うちの場合、自分もリモートワークなのでパパが家にいる時間も多く、パパにも気軽に構ってもらえる環境にある。 だからなのか、これはパパ、これはママというような、指名制度が始まることが多いです。
たとえば着替えでは、シャツはママ、ズボンはパパ。 お風呂に一緒に入るのは、ママ。パジャマを着させるのはパパ。 スープはママ、お米はパパ。
どちらにも気にかけていてほしいのかなと思います。
好き嫌いが多い
子供は誰しもそうかもしれませんが、野菜やお肉などの好き嫌いは多いです。 ご飯(お米)しか食べたくない日もよくあります。
栄養を採ってほしいので、タンパク質やビタミンをなんとか誤魔化して食べさせようとするが、なかなか食べてくれません。
これの何が大変かというと、せっかく良かれと思って料理したご飯が食べてもらえないという精神的ダメージがあります。 細かく刻んだり練り込んだりしても、いらないと言われ結局自分で食べてるのはだいぶむなしいです。
トイレに行かない(トイトレ問題)
3歳になると、そろそろオムツが外れる子も出てきます。 2歳くらいから準備を・・と思うものの、なかなかトイレに行こうとしません。 失敗させて学ぶのが一番だとは理解しつつ、おもらしの片付けに恐れ慄いてまだチャレンジできていません…。
帰りに公園に寄りたい
うちには車や自転車がないので、登園・降園は歩いています。
保育園からの帰り道に公園があり、どうしても寄りたくなってしまいます。
そうすると仕事に戻るのが間に合わなくなったり、その後の工程が遅くなってしまうので早く帰りたいのだけど、なかなか帰ってくれないことも多いです。
自分でやりたい
2歳を過ぎてからは自分でやりたいことも増えてきて、ご飯を食べる、お着替えをするなど、自分でできることも増えてきて良いことではあります。 ただ、子供がやることなので、時間もかかるし失敗も多いです。
親がやることは私もやりたい、なので、自分ではできないこともチャレンジしたくなります。
最近では、ベビーカーを押す、洗濯物を干す、シャンプーをする、などチャレンジしていて、サポートするのが大変です。
他にもパパの目薬をさしてくれたり、薬飲ませてくれたりします。
先日、薬持ったままその手にくしゃみされたときは、むしろマイナスじゃん…と思いました。
親が勝手にやってしまうと「〇〇ちゃんがやりたかった〜!」と怒って泣いてしまうこともあります。
振り返って思うこと
いろいろ大変だなと思うことは書いたものの、 生まれてから今が一番かわいいなと思っています(かわいさを更新し続けている)。
1年でできることもたくさん増えました。走ったり遊んだり喋ったり。人形遊びでおままごとのようなことができたり、お話も非常に上手になりました。会話が成り立つことに驚きの毎日です。
「お花とお鼻、一緒じゃない?」と言葉遊びにも気づき始め、親譲りのギャグセンスを発揮する日も近そうです。
一人でできるようになったことも増えましたが、できないことに対しても「大きくなったら」「3歳になったら」やりたいと言います。
感情移入も豊かで、アンパンマンをみてパパとはぐれたキャラクターを見て泣いたりします。
何よりとても優しく育ってくれているなと思います。 痛がったり咳をしたりすると、「〇〇ちゃんがいるからね、大丈夫だよ」と言ってくれます。
ただ、咳き込んだらいらないのにガムや飴を強要してくることもあり、無駄に飴を舐めていることもあります。
もっとテレビやスマホに頼るなどして、あんまり親が構わないようにすれば、 勝手に一人で遊んだり勝手に一人で寝たりするのかもしれないなとも思います。
ただ、子供が親を構ってくれるのは今のうちなのだと思って、今は大変さも十分に味わって育児しようと思ってがんばります。
コードレビューbotをローカルでお試しする方法
概要
Open AIのプロンプトを活用して自前でコードレビューbotを用意してみたので、備忘のためやったことを書き残しておきます。
きっかけ: GitHub Actions のワークフローが動かない
GitHub で利用できる Code Review 用のワークフローが GitHub Actions のマーケットプレイスで提供されています。
ただし残念ながらうまく動作しませんでした。 具体的にはワークフロー自体は動作するものの、コードレビューはされませんでした。特にログも出力されないので原因はよく分かっていませんが、以下の注意事項が関係しているのかなと予想しています。
Due to cost considerations, BOT is only used for testing purposes and is currently deployed on AWS Lambda with ratelimit restrictions. Therefore, unstable situations are completely normal. It is recommended to deploy an app by yourself.
GitHub - anc95/ChatGPT-CodeReview: 🐥 A code review bot powered by ChatGPT
ワークフローが動けば特にこの記事の作業をする必要はないと思いますし、 他にもワークフローはいくつかありそうなので、探してみて使うのも良いと思います。
この記事は、 anc95/ChatGPT-CodeReview を自前で動かすにはどうすればいいかを記載します。
ローカルで動かすまでの準備
Open AI トークンの準備
ワークフローを使うにせよローカルで動かすにせよオープンAIのAPIキーが必要です。
無料ではできないので注意が必要です。
以下から登録し、ペイメントを登録してキーを発行します。
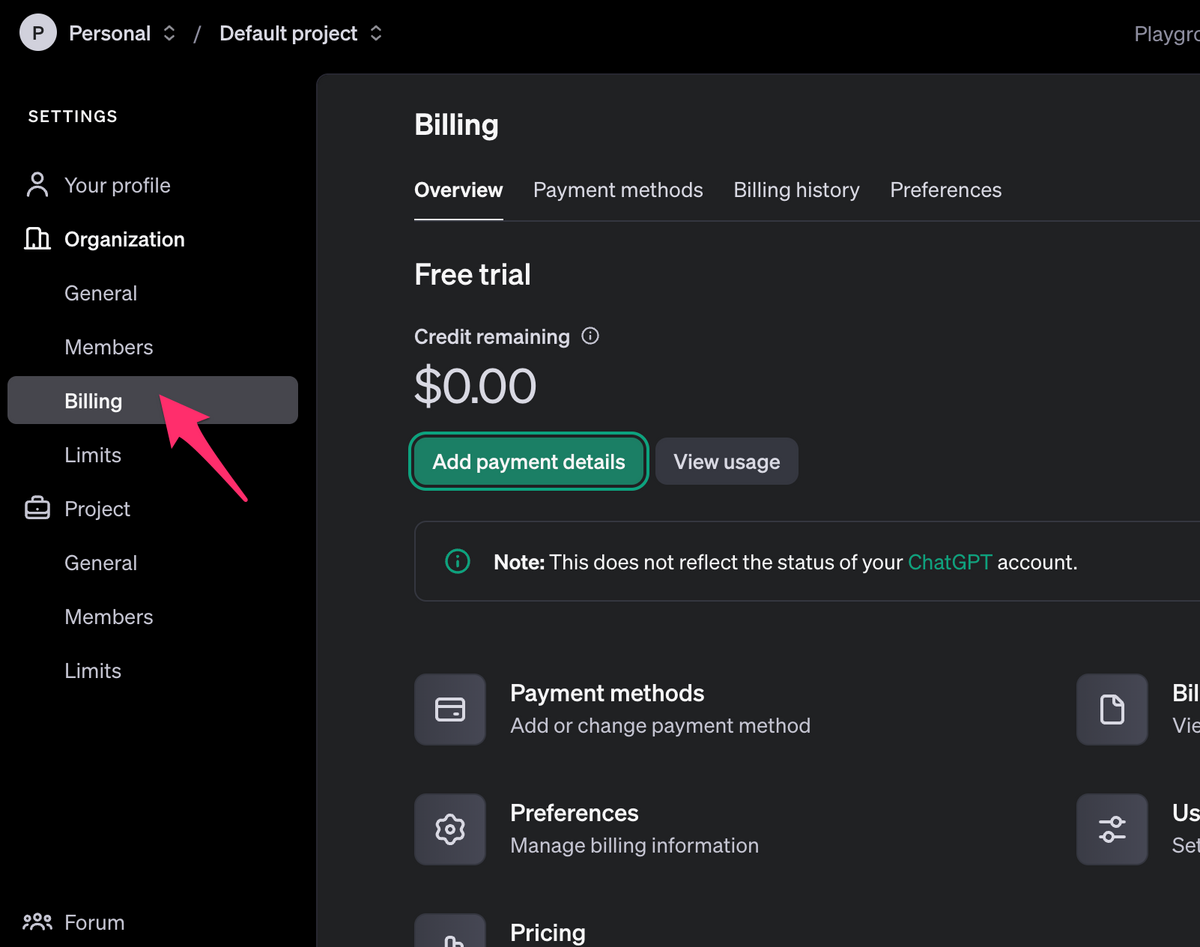
※ 10ドル分登録しましたが、お試しで使うくらいならそんなに入れなくてよかったなと思いました。
ここで作成した API キーをアプリが使う環境変数として .env ファイルの OPENAI_API_KEY という名前であとで追加するため、保存しておきます。
ChatGPT - CodeReview
コードをクローンしたら README に書かれている通りにしてみます。
GitHub - anc95/ChatGPT-CodeReview: 🐥 A code review bot powered by ChatGPT
# Install dependencies npm install # Build code npm run build # Run the bot npm run start
すると、 Probot が動き localhost:3000 で listen し始めてくれます。
> cr-bot@1.0.0 start > node -r dotenv/config ./dist/index.js INFO (probot): INFO (probot): Welcome to Probot! INFO (probot): Probot is in setup mode, webhooks cannot be received and INFO (probot): custom routes will not work until APP_ID and PRIVATE_KEY INFO (probot): are configured in .env. INFO (probot): Please follow the instructions at http://localhost:3000 to configure .env. INFO (probot): Once you are done, restart the server. INFO (probot): INFO (server): Running Probot v12.3.0 (Node.js: v20.11.1) INFO (server): Listening on http://localhost:3000
さらに勝手に .env ファイルが作成されます。
これだけでは動かないので GitHub Apps の登録と設定をします。
GitHub Apps の登録
GitHub Apps に自分専用のコードレビューボットアプリを登録します。
諸々の初期設定は Probot のアプリ経由で実行すると簡単にできます。
npm run start でアプリを実行してある状態で、 http://localhost:3000/ にアクセスします。
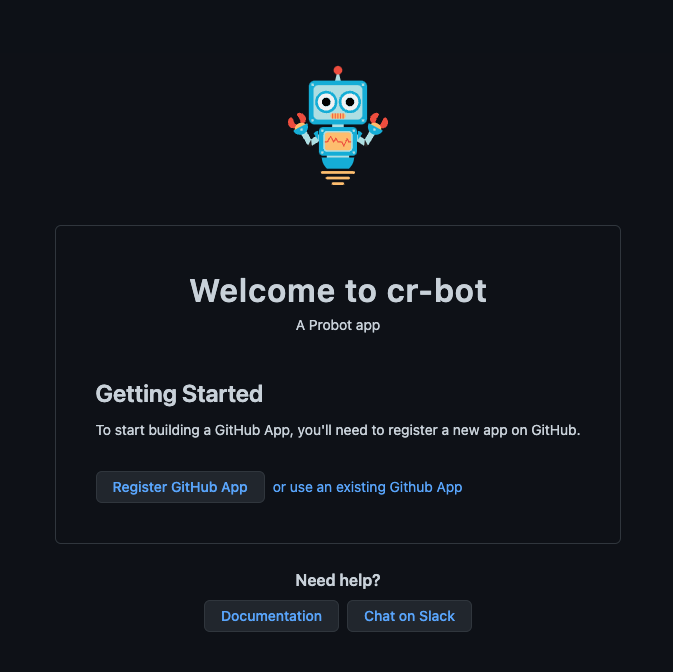
Register GitHub Apps を押下して Apps 登録画面に遷移します。 特に公開もしないので適当にアプリ名を入力します。
画面に沿って設定すると .env に、 APP_ID など必要な環境変数が自動的に追加されている状態になります。
bot への必要な権限追加
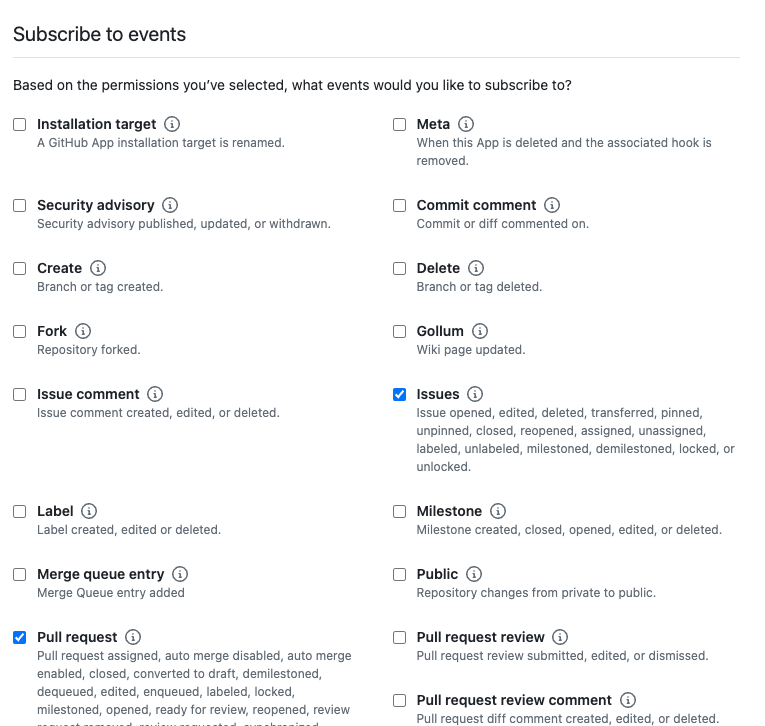
アプリケーションには必要となる権限を与えておきます。
例えば、以下のような設定を入れておくと PR や Issue が作られたときや、コードの変更時に発火できます。
- Repository permissions > Pull requests
- Repository permissions > Issues: read and write
- Repository permissions > Contents: read only
https://github.com/settings/apps/(app-name)/permissions
Subscribe to events の方も忘れずに追加します。
権限の設定が終わったら、アプリが対象のレポジトリにインストールされていることを確認します。
https://github.com/(org)/(repo)/settings/installations
インストールしたら webhook イベントが飛ぶようになるので、アプリの履歴から飛んだWebフックが確認ができます。
https://github.com/settings/apps/(app-name)/advanced
※ 後述する smee の URL (https://smee.io/hogehoge) からも確認できます。
もしイベントが飛んでいないようであれば、追加したパーミッションに対してレポジトリ側の設定でアプリの再承認が必要かもしれません。
Repository → Settings → Installed GitHub Apps → Configure
bot の起動
まずは忘れないように .env ファイルに OPENAI_API_KEY を追加します。
ローカルに立ち上げたサーバーに対して webhook のエンドポイントを提供するサービスとして smee を使います。
.env に追加されている WEBHOOK_PROXY_URL のページにアクセスするとインストール方法と利用方法が表示されます。
$ npm install --global smee-client
smee を起動します。
$ smee -u https://smee.io/hogehoge
アプリを起動します。
$ npm run start
動作確認
インストールしたレポジトリに対してコード編集してからプルリクを作ってみます。
これでコードレビューがされれば成功です。
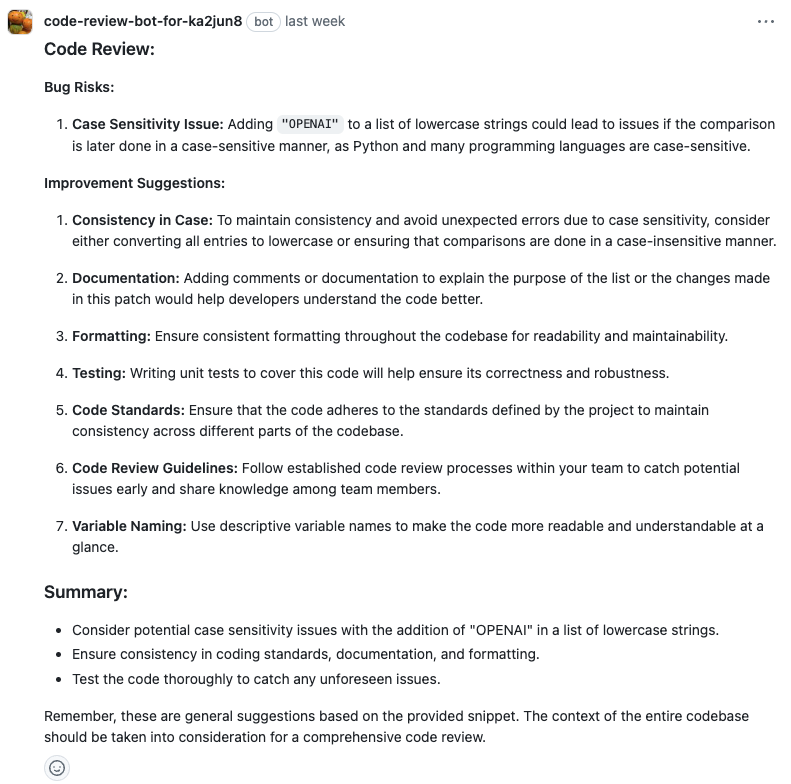
プロンプトや言語も変更ができるので試してみると良いです。
LANGUAGE=Japanese PROMPT='〜な観点でコードレビューをしてください。'
まとめ
コードレビューボットをローカルで実行して動くようにしました。 自分が作業するときだけお試しで実行したかったので、これで一旦完了です。
実際にちゃんとセルフホストすることを考えると、どこかにデプロイするなりして動かす必要があるので、もし実施したらまた記事にします。
グリッドレイアウト内の要素の横幅の決まり方と三点リーダーを表示させる方法をきちんと理解する
はじめに
Web 開発における CSS のグリッドレイアウトで構成された要素に対して、三点リーダー表示がうまくいかないケースがありました。 今回グリッドレイアウトにおけるグリッドアイテム(グリッドトラック)の横幅の決まり方を勉強したので、備忘のために記事に残しておきます。
サンプルコードはこちらに載せています。
Grid+Ellipsis_example - StackBlitz
三点リーダーはどのように表示するか?
まず、今回対象とする三点リーダーを表示する方法を以下に記載します。
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
overflow: hidden;は、要素の横幅が親の横幅を超えた場合に、横スクロールさせないようにします。text-overflow: ellipsis;は、要素が横にはみ出た分を三点リーダー表示に変える指示になります。white-space: nowrap;は、要素が横にはみ出る際に折り返して二行以上になることを防ぐための指示になります。
これら三つの指示により、中身のコンテンツが要素の横幅を超えて溢れる場合に三点リーダーが表示されます。

text-overflow - CSS: カスケーディングスタイルシート | MDN
フローレイアウトにおけるブロック要素の横幅の決まり方
ブロック要素に対して明示的な横幅 (width) の指定がない場合、初期値は auto になります。
また、最小の横幅 min-width も同様に初期値は auto です。
width が auto の場合、親要素の横幅になります。
親要素がない場合(最上位の場合)、要素の横幅はビューポートと同じになります。
つまり、端末やブラウザの横幅と同じになります。
また、この時最小の横幅(min-width)は 0 として処理されます。 言い換えると、この要素は横幅がゼロになるまで短くなり得ます。

本来の要素の横幅を超えるようなコンテンツを表示させようとする場合に、 コンテンツは横幅から溢れると判断されて、三点リーダーが表示されることになります。

グリッドレイアウトにおけるブロック要素の横幅の決まり方
グリッドレイアウトは、要素に対して display: grid; のプロパティを指定することで、その子要素を柔軟に並べることができるものです。
この記事ではグリッドレイアウトについては詳細を記述しません。末尾に示す参考文献をご覧ください。
グリッドレイアウトでは、グリッド指定した要素の子要素たちをグリッドアイテムと呼び、暗黙的にグリッドアイテムを並べるためのグリッドトラックが構成されます。
グリッドトラックの横幅のサイズは、明示的に指定されないと auto になります。
しかし、ここでいう auto は フローレイアウトにおけるブロック要素で暗黙的に指定されるデフォルト auto とは動きが異なります 。
具体的には以下のルールで最小の横幅が決まります。
グリッドアイテムが、
- スクロールコンテナではない
- 最小トラックサイズが「auto」なトラック(複数のトラックをまたぐ場合は1つ以上が「auto」なトラック)に配置されている
- 複数トラックにまたがって配置されている場合、それらにフレキシブルなトラック(最大トラックサイズを fr で指定したもの)がない
の全ての条件を満たす場合、横幅の最小値 は min-content になります。*1
言い換えると、この場合コンテンツの横幅以下にはなりません(つまり要素の横幅を溢れようがない)。
条件を一つでも満たさない場合は、横幅の最小値は 0 になります。 フローレイアウトにおけるブロック要素と一緒の考え方になります。

ちなみに、理由は後述しますがこの要素の配置であれば三点リーダーは意図通りに表示されます。
グリッドレイアウトで子要素の三点が表示されるとき・表示されないとき
表示されない時
ややこしいのですが、以下のようなケースでは三点リーダーが意図通りに表示されません。
- 一番下の子要素が三点リーダー表示のスタイルを持っている
- その親の要素は単にブロック要素になっている
- その親(子から見て祖父母)の要素がグリッドレイアウト指定をしている
- それぞれ明示的に横幅 (
widthやgrid-template-columns) を指定していない

これは、三点リーダーを表示するはずの要素の親の横幅が自身の横幅と同一になってしまうため、横幅が溢れているという状態にならないためです。
親より上のレイアウトが影響してしまうため、三点リーダーを表示させる要素自体は問題ない場合も多々あります。 その場合例えば Storybook で用意したコンポーネントでは三点リーダーが表示されているが、実際のページ側でグリッドレイアウトで配置されて三点リーダーが表示されなくなる、ということが起きうるので注意が必要です。
表示される時
グリッドレイアウト内の要素の三点リーダーを表示するためには、上記で示したルールを一つでも満たさなければフローレイアウトにおけるブロック要素と同じ条件になるので、三点リーダーが表示されます。
例えば、
- 親要素にも overflow hidden; を指定してスクロールコンテナにする (図の解決策①)
- 親のグリッドレイアウト指定で グリッドアイテムの横幅を明示的に指定する (図の解決策②)
- width や min-width で明示する方法もあるが、grid-template-columns をせっかくなら使いましょう。
- minmax(0, 1fr) のような記載でも可です。
- 複数トラックにまたがる場合には、どこかに 1fr を指定しておく
が挙げられます。

overflow: hidden; はスクロールできないようにするプロパティなので、直感的にはスクロールコンテナではないと思われるかもしれません。
しかし 仕様上は overflow: hidden; はスクロールコンテナとしてみなされます。
補足ですが、overflow: clip にすると hidden と同じ効果を得られてかつ、スクロールコンテナではないとみなされます。
overflow - CSS: カスケーディングスタイルシート | MDN
ややこしいのですが、display grid が三点リーダー要素の直接の親になっている場合は、子要素に overflow: hidden; があるのでスクロールコンテナとみなされて、正しく三点リーダーが表示されます。
そのため、上記の「グリッドレイアウトにおけるブロック要素の横幅の決まり方」の例で挙げていた要素の並びでは三点リーダーが表示されていました。
まとめと感想
フローレイアウト、グリッドレイアウトにおける要素の横幅の決まり方、またグリッドレイアウトで三点リーダーを意図通りに表示するために理解すべきことを書きました。
グリッドアイテムのサイズの決まり方を理解するのは動かしながら見てみて、最初は難しかったです。
一見よく分からない挙動に見えるのですが、グリッドと仲良くなれば理解もできるので、今後もグリッドと仲良く頑張ろうと思います。
参考文献と謝辞

グリッドレイアウトは慣れると非常に便利で使いやすい仕組みなので、上記本をぜひ読んでみてください。
※ エビスコムの担当者の方にもコメントをいたたき、大変参考になりました。ありがとうございます。
App Router移行時に0.01%の確率でCSR遷移が404エラーになる
概要
Pages Router から App Router 移行時に一部既存の画面での CSR 遷移が 404 エラーになりました。
この件について調査したので、記事にしてまとめておきます。
前提
今回発生したバグの内容の再現環境の特徴として、以下が挙げられます。
- Next v13.5.6
- Base path の設定あり
- App Router と Pages Router が共存している
Base Path について
Base Path の設定は next.config.js に以下のような記載があると、
module.exports = {
basePath: '/base',
}
/pages/examples.tsx で配置したページコンポーネントが、
URL /base/examples で閲覧できるようになるものです。
また以下のような Link コンポーネントは、自動的に Next.js によって
<Link href="/examples">Example Page</Link>
/base/examples に画面遷移するようなリンクに置き換えてもらえます。
システムの制約上、我々のアプリでは Base Path の設定が必要だったためこの設定を入れています。
実際に起きたこと
特定の画面Aへの画面遷移で 404 のエラーが発生するようになりました。
原因調査
調査したところ以下のことがわかりました。
- 404 エラーになるのは、 Base Path が二重に付与されているため発生する (ex.
/base/base/examplesになってしまう) 。 - URL 直遷移では問題が発生せず、CSR によるクライアントルーティングでのみ発生する。
- ローカルでの実行時
next devでは発生しない (next build & next startで発生する) 。 - 画面A へのリンクのパスは間違っていない。
- App Router との共存をやめると発生しなくなる。
原因の深掘り
原因背景
我々のアプリは基本的に Pages Router を使って開発されています。
このエラーが発生する1つ前のリリースで、将来的な App Router 移行を見据えて、試験的に1画面での App Router リプレイスを実施しました。
つまり、このエラー発生時から App Router と Pages Router の共存状態 になっていました。
ちなみに該当の App Router 化した画面単体で見ると、機能・UI の変更は一切なく E2E テストを用意した上での移行だったこともあり、デグレを発生させずにリリースすることができていました。
しかし、この Pages Router と App Router との共存が起きてしまったことで、全く関係のない画面での画面遷移で 404 エラーが発生 することになりました。
Next.js のクライアントルーティング内部ロジック
Next.js では App Router と Pages Router が共存して存在する場合、 Pages Router からの画面遷移で該当のパスが App Router かどうかハンドリングする箇所があります。
ここには Bloom Filter が使われています。
この Bloom Filter は確度高く判別するわけではなく、ある程度高速に該当のリンクパスが App Router か Pages Router のものか判別するために使われています。 この機能は 0.01% の確率で False Positive する ことが明記されています。
Next.js のドキュメント
Routing: Linking and Navigating | Next.js
実際のコード
なぜ 0.01% の確率で False Positive してもいいかというと、結果的に実行される処理は同じだからだと思われます。
クライアント側で CSR でのルーティング時に Bloom Filter によるフィルタ処理が走って、
- マッチした場合、エラー表出なしで適切にソフトナビゲーション・ハードナビゲーションが行われる
- マッチしなかった場合、エラー表出した上でハードナビゲーションが行われる
という動きになります。
つまり、結果的に該当のパスにはハードナビゲーションされるので、最低限のユーザーへの機能提供は担保されているという想定だと思われます。

Base Path 設定 x App Router 共存時の問題
しかし、ここで Base Path 設定がついている場合には問題が発生します。
すでに Base Path が付与された状態でフィルタ判定されるにも関わらず、ハードナビゲーションの処理に対して、再度 Base Path を付与するような処理が入っています。
つまりこれによって、 Base Path が二重に付与されてしまうことでハードナビゲーションし直されたとしても該当の画面が存在しない 404 エラーになる、という現象が起きてしまっていました。

解決策(ワークアラウンド)
こちらはすでに下記の Issue により報告されています。
しかしながら、上記 Base Path の付与ロジック部分の修正ではなく、このフィルタ機能自体をオフにすることが紹介されています。
// next.config.js
experimental: {
clientRouterFilter: false,
},
本質的な解決策ではないものの、結果的にこのワークアラウンドによって問題は解消されてはいます。
Next.js v13.5.6 でのエラー率
実はこの問題は上記で 0.01% と書いていたものの、我々のアプリの Next.js のバージョンである、 v13.5.6 ではエラー率は 1% でした。
現在の v14 系以降ではエラー率が見直され、 0.01% にまで下がっています。
これによって、我々のアプリではより顕著に問題が発生しやすくなっていたという問題もありました。
雑記
ちなみに、自分の理解が間違っていなければ Base Path が設定されている場合、 App Router 側に配置しているパスに対しても適切にハンドリングができていないと思われます。
getRouteInfo で Base Path を取り除いたパスを取得するはずですが、
getRouteInfo 内で Pages Router 側の build manifest からは App Router 配下の manifest は取得できないので、エラーがスローされます。
これによって、結果としてエラーが出力されてハードナビゲーションされる、という動きになっていると思われます。
おわりに
Pages Router から App Router 移行時に一部既存の画面での CSR 遷移が 404 エラーになってしまったバグを調査してまとめたものを記事に残しました。
Base Path の設定がある状態で、Pages Router と App Router の共存状態を作る場合には注意した方が良さそうです。
現在は 0.01% の確率で False Positive するだけなので危険性は低いものの、 clientRouterFilter オプションはオフにしておいた方が無難かなと思いました。
Next.js の Bloom Filter での False Positive が実際に発生することを確認したレポジトリ
react-testing-library の `act` と `waitFor` を使うべきタイミング
はじめに
react-testing-library を使うと React アプリケーションのコンポーネントの挙動をテストすることができます。
詳しくは公式ドキュメントを読んでください。
https://github.com/testing-library/dom-testing-library testing-library.com
ただ、react-testing-library は若干厄介なところがあり、 state の更新や非同期な処理が含まれる挙動をテストしたい場合に、 React と react-testing-library の挙動を理解していないとテストが思ったように動作しない、という経験をした人もいることと思います。
こういう場合に、 act で処理を囲ったり、 waitFor で処理を囲うことで「なぜか分からないけどテストが動いた」という経験がある人もいるのではないでしょうか。
僕もそうです。
react-testing-library の動きを少しでも理解を深めるために、よく対処方法として上がる act と waitFor について調べたのでまとめておきます。
react-testing-library
react-testing-library 自体には対したコード量はありません。
src ディレクトリ配下: react-testing-library/src at main · testing-library/react-testing-library · GitHub
react-testing-library 自体は、 react を render して HTML DOM を用意したり、イベント発火時に act を囲うようにする程度です。
実際のコンポーネントテストのイベントモック関数自体は testing-library の共通関数 (user-events など) を使うことになると思います。
act の概要
React のコンポーネントをテストしようとした際に、該当の処理コードを act で囲めよという警告が出ることがあります。
Warning: An update to XXX inside a test was not wrapped in act(...). When testing, code that causes React state updates should be wrapped into act(...): act(() => { /* fire events that update state */ }); /* assert on the output */
React の act については、警告の中にもある通り、このドキュメントに辿り着きます。
ただこれだけ読んでも分かるようで分かりません。 react-testing-library で act を呼び出しますが、実体は React 本体にあります。
- react-testing-library の act の実装はここになります。
- これは、 React (
react-dom) のテスト用のユーティリティ(test-utils) の act を呼んでいます。 react-domのtest-utilsの act はReact.unstable_actを呼んでいます。- 結局
actの本体は、 ReactAct というコードで、 React 本体が用意してくれているロジックになります。
元々出ていた警告も、 react-testing-library などの testing-library 系のコードが出力しているわけではなく、 React 本体のコードが出力しています。
act については、この記事や記事内でも参照されている Example を読むと概要が理解できます。
簡単にまとめると以下だと理解しました。
- React の状態(ステート)の更新があった際に仮想 DOM への反映が同期的に行われても、実 DOM へのレンダリングコミットは非同期的に行われている。
- 非同期で行われる全ての実 DOM のレンダリングコミットの完了を待たずに
expectしてしまうと、意図しない実 DOM の UI 状態でテストをしてしまう。 actメソッドで該当のレンダリング処理が走るコールバックを囲うことで、コールバック内での実 DOM 反映のレンダリングコミット処理が全て完了するのを待つ。- これにより、 テストするための実 DOM の UI 状態が意図したものになり、正しく
expectを実施することができる。

act の内部実装
さらに実際の act の内部の動きは、この記事に詳しく解説されています。
act 関数ではおおよそ以下の動きをしているようです。
ReactCurrentActQueueというキューを用意しておく。- 与えられたコールバックを実行してレンダリング処理をした際に発生した状態更新による Fiber の UI 更新処理を
ReactCurrentActQueueにキューイングする。 - (ここから正確に読み解けなかったけど) スケジューリングされた UI の更新時に、キューイングしておいたものを
flushActQueue関数で全て実行する。 - ↑で flush し終えたら act を resolve する。
こういう動きが内部的に行われているので、 act によって状態の整合性が正しく保たれることが(なんとなくですが)理解できました。
ちなみに、冒頭の warning が表示されている箇所では ReactCurrentActQueue.current が null である(つまりキューが初期化されていない)ことを確認しているようです。
Fiber の UI 更新処理が実施されるタイミングで、キューが空ならおかしいってことなんでしょうか(わからん)。 React-testing-library のテストの時はわかったんですが、普通に npm run dev の時も内部的に act されているってことですか?詳しい人教えてください。
user-event は act を呼んでいる
react-testing-library のコンポーネントテストを実現する際には、testing-library の user-event を使ってユーザーの操作イベントをモックすることがあります。
軽く調査すると user-event は act で囲われているので自前で囲う必要はない、といった内容の記述が見られます。
これを具体的にコードで追うと、
user-event は dispatchEvent で呼び出される wrapEvent で @testing-library/dom の設定値である eventWrapper を呼び出します。
その eventWrapper という設定値を react-testing-library で定義しています。
ここで指定されたコールバックを act で囲うようになっています。
これによって userEvent.click を何も気にせずに使ったとしても、 act で囲われた状態で利用することができています。
ステートが非同期で更新されるケースには act では対応できない
userEvent.click が act で囲われているにも関わらず、 act で囲えという警告が出ることがあります。
これは大抵の場合、ステートが非同期に更新されてしまっていることによるものだと考えられます。
例えば、
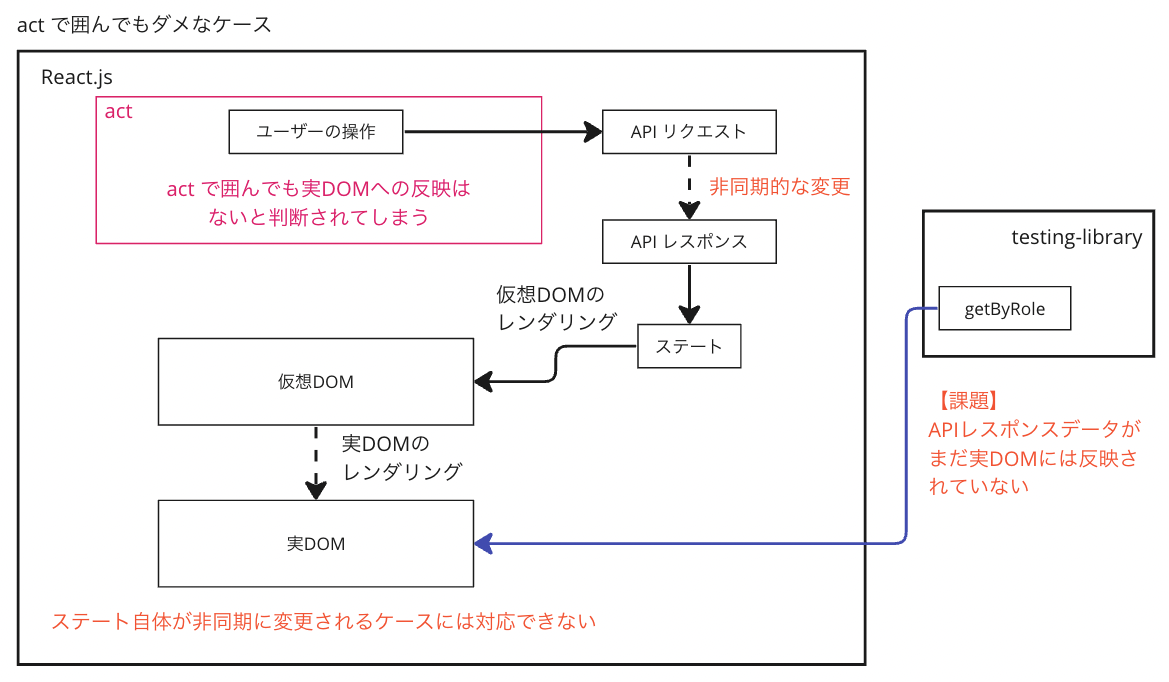
上記のように、レンダリングコミットではなくステートの更新自体が非同期的に行われてしまうと、 act では対応しきれないようです。
これを対処するためには、 act で sleep 処理を挟むという手が取れそうです。
await act(async () => {
await sleep(1100); // wait *just* a little longer than the timeout in the component
});
react-act-examples/sync.md at master · threepointone/react-act-examples · GitHub
これによって act で挟んでいる sleep 中に API のレスポンスが返ってきて UI が更新されれば、 expect が正しく動くことにはなりそうです。
waitFor を使う
しかし act で sleep を囲うくらいなら、 waitFor を使うという手が取れそうです。
waitFor のコードは以下です。
dom-testing-library/src/wait-for.js at main · testing-library/dom-testing-library · GitHub
デフォルトの設定では、 1秒間の間 50 ms ごとに expect を繰り返すことで DOM 反映を待ってくれます。
これを挟み込んでおけば非同期的なステート更新にもおおよそ耐えうることになりそうですね。
ただ、本来的には時間に左右されるような処理にはさせたくないですが、ある程度仕方のないことかもしれません。
findBy 系のメソッドは waitFor も実行している
ちなみに findByRole のような findBy 系のメソッドは waitFor を呼んでいます。
Async Methods | Testing Library
これによって非同期的な UI 更新がなされる場合、 getByRole では動かなかったテストコードが findByRole では動くということが起きます。
おわりに
react-testing-library の act と waitFor 、またそれに関わるメソッドなどについて調査しました。
- act: React が提供する実 DOM へのレンダリングコミットを待ってくれる仕組み
- waitFor: 1秒間の間にたくさん expect しながら待ってくれる仕組み
また分からなくなったときに気が向いたら追調査してみようと思います。
Langchain の要約API load_summarize_chain (Map-Reduce) 詳解
はじめに
GPT 系で要約を実施するために、 Langchain の API (load_summarize_chain の map_reduce オプション ) を利用する機会がありました。そのために周辺の記事などを少し眺めてみる機会があったのですが、適切な解説記事がなかったため今回執筆してみることにしました。
筆者は LLM や生成 AI 、ましてや機械学習、ディープラーニング、そもそも Python にも詳しいわけではないため、一部事象を誤解していたり、間違った解説をしている可能性があります。 ご容赦いただくとともに、間違っている点についてはご指摘いただけると幸いです。
前提
LLM (Large Language Model) は文章を要約することにも利用可能です。 しかし、LLM には基本的に一度に処理できるトークン数の最大値 (Context Window) が決められています。
Context Window のお話 - Speaker Deck
OpenAI の GPT の Context Window は公式ドキュメントで確認できます。
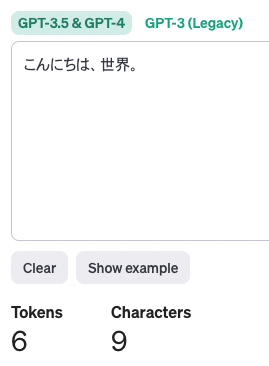
モデル gpt-4 で 8,192 tokens です。
1 トークンでどの程度の文字列なのかは、確かめることができる Tokenizer があるので、試してみるとわかりやすいです。
https://platform.openai.com/tokenizer
LLM には Context Window があるため、Context Window を超えてしまう長い文章をインプットとして扱いたい際には工夫が必要になります。
その一つが Langchain の load_summarize_chain の Map-Reduce オプションです。
詳しくは Summarization | 🦜️🔗 Langchain か、以下に示す参考記事を読んでいただく方がより理解が進むと思います。
今回の記事では、Map-Reduce の処理がどう実施されており、入力の引数に渡すべき
map_promptcombine_promptcollapse_prompt
にそれぞれどういうプロンプトを渡すことが求められているのか?の参考になれば幸いです。
参考にした記事
- Summarization | 🦜️🔗 Langchain
- LangChain の長い文章を扱う方法 | Hakky Handbook
- OpenAI API で開発してての学び
- LangChainのSummarizationについて調べたまとめ - まったり勉強ノート
要約処理の解説
長い文章を要約するためには、大きく二つの工程が必要になります。
- 文章の分割処理
text_splitter - 分割された文章の要約処理
load_summarize_chain
text_splitter は指定されたチャンクサイズで文章を分割してくれる API です。
TokenTextSplitter | 🦜️🔗 Langchain
今回は text_splitter については詳しくは触れません。
要約 API load_summarize_chain
長い文章を分割したドキュメント (i.e. documents) を要約するために、 load_summarized_chain API を利用します。
load_summarized_chain には、
- Stuff
- Map-Reduce
- Refine
の3種類のオプション (chain_type) があります。
Stuff オプション
このうち、 Stuff オプションは当初の課題である 「要約したい文章か Context Window を超えてしまっている場合にも要約したい」という課題はクリアしていません。 引数として複数の documents を渡す作りにはなっていますが、呼び出す側があらかじめ Context window を超えない形で複数の documents に収えておく必要があります。
内部の挙動としては、引数で受け取った複数の documents を改行コードで結合し、大きい一つの文章にして LLM に投げています。
ちなみに後述しますが、 Map-Reduce オプションの中で Stuff Chain が使われています。
Map-Reduce オプション
Map-Reduce オプションは、それぞれの分割したドキュメントに対して LLM にて要約処理を実施 (Map 処理) し、それらの結果を結合して 1つの要約を再度 LLM にて処理を行う (Reduce) 方式になっています。
Refine オプション
Refine オプションは時間の関係で調べられていません。ごめんなさい。
load_summarize_chain の Map-Reduce オプション
Map-Reduce オプションでは、 map 処理と reduce 処理に分かれて処理が実施されます。
map処理では、それぞれのドキュメントに対してmap_promptで LLM を呼び出します。reduce処理では、要約したそれぞれの新しいドキュメントを結合したものを再度要約処理します。
上記を図示すると、以下のようになります。
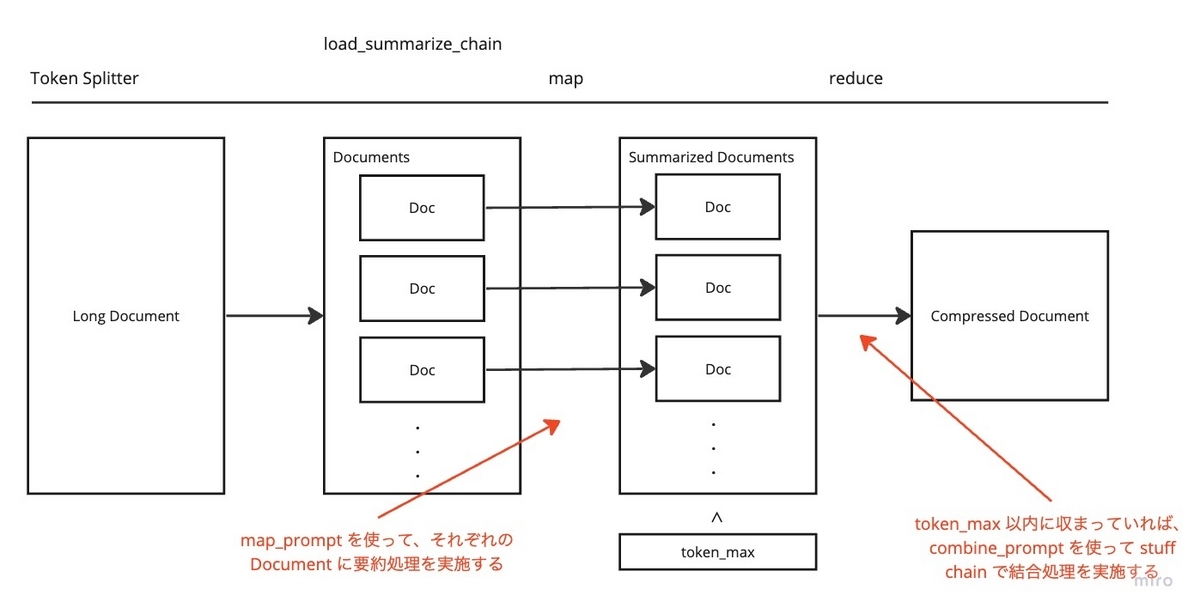
この時、load_summarize_chain を呼び出す際に指定した引数の token_max を超えない場合には collapse 処理は行われません。つまり collapse_prompt は利用されません。
続いて、一度 map 処理で生成した documents のリストが token_max を超える場合です。
この場合上記のベーシックな挙動に加えて、 collapse 処理が行われます。
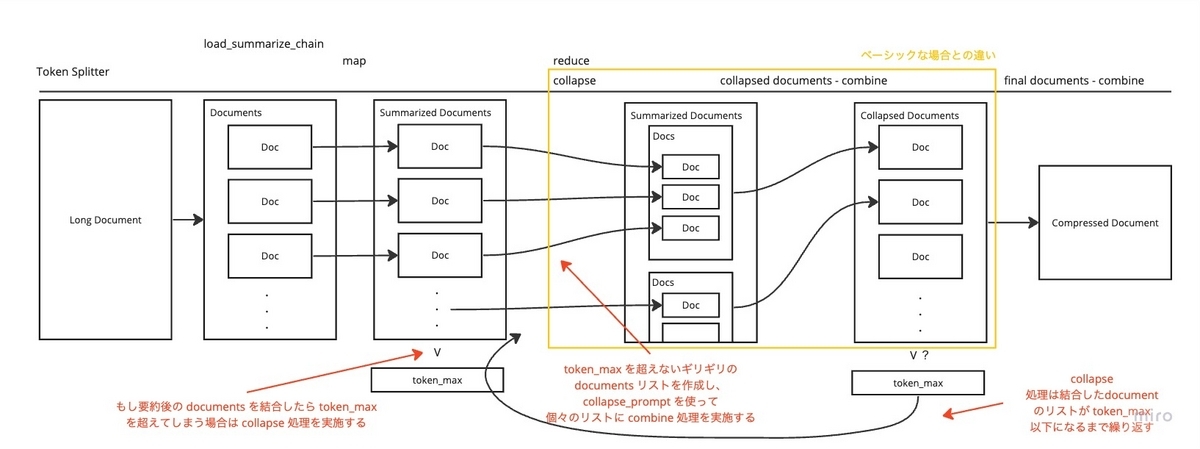
collapse 処理では、map した結果の documents から、token_max を超えないギリギリの document のリストを作ります。
新たに括った 「token_max を超えないギリギリの document のリスト」で collapse_prompt で combine 処理と同様の LLM の要約処理を実行します。
ちなみに、
- チャンクサイズが大きく map した結果が
token_maxを超えていた場合で、 collapse 処理でも map したリストの数と変わらずまだなおその文章がtoken_maxを超えてしまっていると、無限ループになる恐れがあります。 collapse_promptは指定しないとcombine_promptが使われますが、これは collapse 処理が combine 処理と似た処理を実施ているからになります。
以上が、 load_summarized_chain の Map-Reduce オプションの挙動を調査した内容になります。
まとめ
今回の記事では、load_summarized_chain の Map-Reduce オプションの挙動を調査しました。
map_promptcombine_promptcollapse_prompt
のそれぞれでどういうプロンプトを用意すると良いか参考になると幸いです。
もし何か間違っている点があれば、ご指摘ください。