はじめに
GPT 系で要約を実施するために、 Langchain の API (load_summarize_chain の map_reduce オプション ) を利用する機会がありました。そのために周辺の記事などを少し眺めてみる機会があったのですが、適切な解説記事がなかったため今回執筆してみることにしました。
筆者は LLM や生成 AI 、ましてや機械学習、ディープラーニング、そもそも Python にも詳しいわけではないため、一部事象を誤解していたり、間違った解説をしている可能性があります。 ご容赦いただくとともに、間違っている点についてはご指摘いただけると幸いです。
前提
LLM (Large Language Model) は文章を要約することにも利用可能です。 しかし、LLM には基本的に一度に処理できるトークン数の最大値 (Context Window) が決められています。
Context Window のお話 - Speaker Deck
OpenAI の GPT の Context Window は公式ドキュメントで確認できます。
モデル gpt-4 で 8,192 tokens です。
1 トークンでどの程度の文字列なのかは、確かめることができる Tokenizer があるので、試してみるとわかりやすいです。
https://platform.openai.com/tokenizer
LLM には Context Window があるため、Context Window を超えてしまう長い文章をインプットとして扱いたい際には工夫が必要になります。
その一つが Langchain の load_summarize_chain の Map-Reduce オプションです。
詳しくは Summarization | 🦜️🔗 Langchain か、以下に示す参考記事を読んでいただく方がより理解が進むと思います。
今回の記事では、Map-Reduce の処理がどう実施されており、入力の引数に渡すべき
map_promptcombine_promptcollapse_prompt
にそれぞれどういうプロンプトを渡すことが求められているのか?の参考になれば幸いです。
参考にした記事
- Summarization | 🦜️🔗 Langchain
- LangChain の長い文章を扱う方法 | Hakky Handbook
- OpenAI API で開発してての学び
- LangChainのSummarizationについて調べたまとめ - まったり勉強ノート
要約処理の解説
長い文章を要約するためには、大きく二つの工程が必要になります。
- 文章の分割処理
text_splitter - 分割された文章の要約処理
load_summarize_chain
text_splitter は指定されたチャンクサイズで文章を分割してくれる API です。
TokenTextSplitter | 🦜️🔗 Langchain
今回は text_splitter については詳しくは触れません。
要約 API load_summarize_chain
長い文章を分割したドキュメント (i.e. documents) を要約するために、 load_summarized_chain API を利用します。
load_summarized_chain には、
- Stuff
- Map-Reduce
- Refine
の3種類のオプション (chain_type) があります。
Stuff オプション
このうち、 Stuff オプションは当初の課題である 「要約したい文章か Context Window を超えてしまっている場合にも要約したい」という課題はクリアしていません。 引数として複数の documents を渡す作りにはなっていますが、呼び出す側があらかじめ Context window を超えない形で複数の documents に収えておく必要があります。
内部の挙動としては、引数で受け取った複数の documents を改行コードで結合し、大きい一つの文章にして LLM に投げています。
ちなみに後述しますが、 Map-Reduce オプションの中で Stuff Chain が使われています。
Map-Reduce オプション
Map-Reduce オプションは、それぞれの分割したドキュメントに対して LLM にて要約処理を実施 (Map 処理) し、それらの結果を結合して 1つの要約を再度 LLM にて処理を行う (Reduce) 方式になっています。
Refine オプション
Refine オプションは時間の関係で調べられていません。ごめんなさい。
load_summarize_chain の Map-Reduce オプション
Map-Reduce オプションでは、 map 処理と reduce 処理に分かれて処理が実施されます。
map処理では、それぞれのドキュメントに対してmap_promptで LLM を呼び出します。reduce処理では、要約したそれぞれの新しいドキュメントを結合したものを再度要約処理します。
上記を図示すると、以下のようになります。
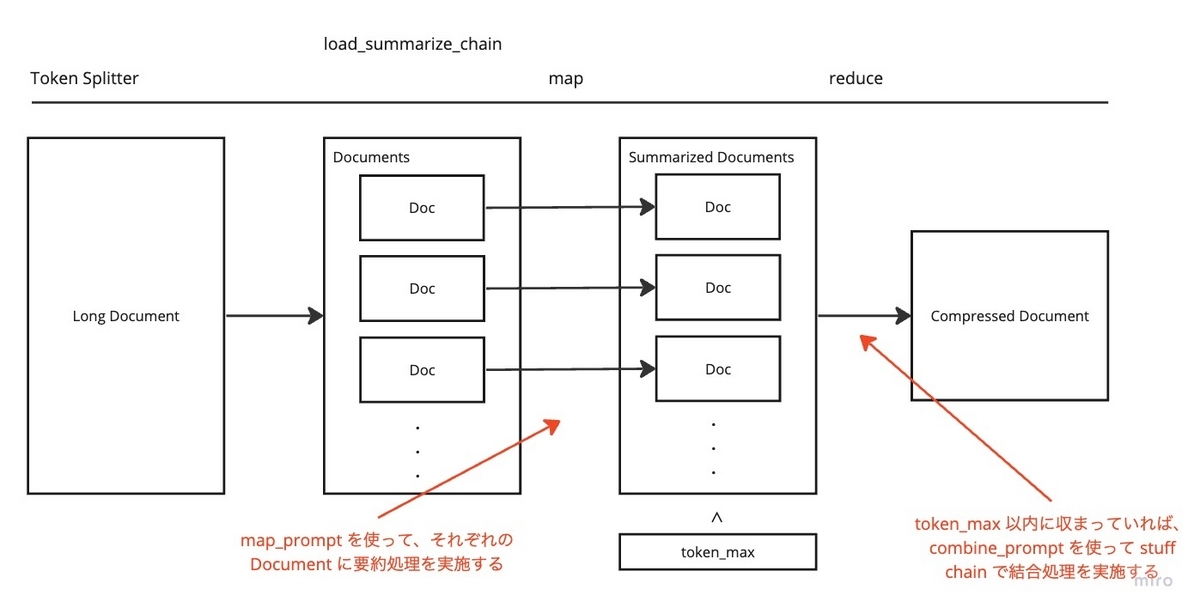
この時、load_summarize_chain を呼び出す際に指定した引数の token_max を超えない場合には collapse 処理は行われません。つまり collapse_prompt は利用されません。
続いて、一度 map 処理で生成した documents のリストが token_max を超える場合です。
この場合上記のベーシックな挙動に加えて、 collapse 処理が行われます。
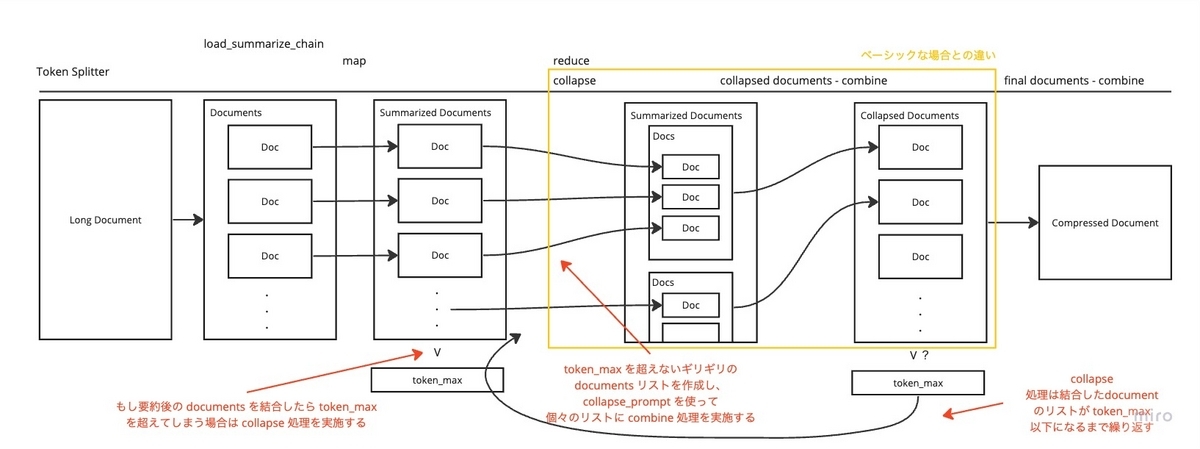
collapse 処理では、map した結果の documents から、token_max を超えないギリギリの document のリストを作ります。
新たに括った 「token_max を超えないギリギリの document のリスト」で collapse_prompt で combine 処理と同様の LLM の要約処理を実行します。
ちなみに、
- チャンクサイズが大きく map した結果が
token_maxを超えていた場合で、 collapse 処理でも map したリストの数と変わらずまだなおその文章がtoken_maxを超えてしまっていると、無限ループになる恐れがあります。 collapse_promptは指定しないとcombine_promptが使われますが、これは collapse 処理が combine 処理と似た処理を実施ているからになります。
以上が、 load_summarized_chain の Map-Reduce オプションの挙動を調査した内容になります。
まとめ
今回の記事では、load_summarized_chain の Map-Reduce オプションの挙動を調査しました。
map_promptcombine_promptcollapse_prompt
のそれぞれでどういうプロンプトを用意すると良いか参考になると幸いです。
もし何か間違っている点があれば、ご指摘ください。